머신 러닝 학습 과정 (1/2)
1. 문제이해
문제를 풀 때 데이터와 가능한 작업량을 미리 분석하는 것
- 문제의 정의
- 데이터 수집과정
- 데이터 수집의 시간
- 전처리의 유무
2. 데이터셋 정의 및 획득
ETL 프로세스
ETL(Extract, transform, load)은 단어대로 추출, 변환, 적재를 하는 프로세스빅데이터를 분석하기 위해서 필요한 전처리 과정
데이터를 추출 후 분석할수 있게 변환하여 적재하는 과정
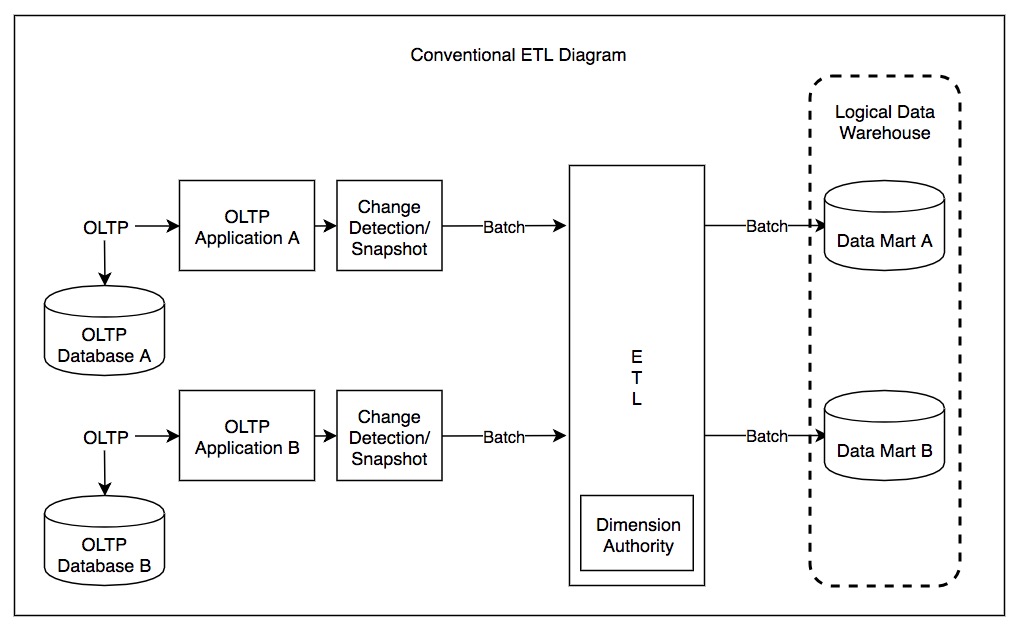 |
| 전통적인 ETL 다이어그램 |
SciPy 및 pandas 를 사용한 데이터셋 로드 및 탐색 분석
3. 피처 엔지니어링
- 가공전 데이터를 가져와서 모델이 일반화 하기 쉬운 형태로 변환하는 과정
- 예측 모델의 정밀도를 향상시키기 위해 학습용 원시 데이터를 기반으로 피처를 변환, 추출, 선택하거나 새로운 피처를 생성하는 작업
누릭된 데이터 다루기
불완전한 데이터셋이 있을때 누락된 부분은 모델에 도움이 되지 않는다. 따라 결측치를 처리하는 방법이 필요함
기본적으로 아래의 방법을 행함
- 해당 결측치행을 제거하여 학습에 사용하지 않는것
- 데이터의 평균을 사용하여 결측치에 넣는것
- 해당 열의 중앙값 사용
- 해당 열의 빈번한 값을 사용
하지만 위의 방법으로 학습이 안될 가능성이 있기 때문에 적중률을 높이기 위해 좀더 고급기술을 사용한다. 누락된 값(결측치)에 대한 상세한 처리 방법은 결측치 처리 블로그 에서 확인해주시기 바랍니다.
원핫 인코딩 (One-Hot Encoding)
하나의 값만 True(1)이고 나머지는 모두 False(0)인 인코딩
머신러닝에서는 수치로된 데이터만 이해할수 있기 때문
보통 자연어 처리 부분에서 사용함
4. 데이터셋 전처리
정규화 및 피처 크기 조정
데이터 정규화를 통해 최적화 기법, 특히 반복적인 기법을 사용할 때보다 잘 수렴하고 데이터를 쉽게 관리할 수 있음
정규화를 했으면 모델 정의후 평가 시 결과 데이터를 역정규화를 해서 데이터의 특성을 잃지 않게 하는 것이 중요
- 정규화 또는 표준화
데이터셋에 정규 분포의 특성, 즉 평균 0과 표준 편차 1을 부여하는 것을 목표로 함
수식 : (각데이터값 - 평균) / 표준편차
정규화와 표준화에 대해 간락히 소개한 블로그
참고

https://docs.scipy.org/doc/scipy/reference/generated/scipy.misc.imread.html#scipy.misc.imread
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.imshow.html
https://programmers.co.kr/learn/courses/21/lessons/11043
https://brunch.co.kr/@rapaellee/4
https://m.blog.naver.com/PostView.nhn?blogId=magnking&logNo=221282668005&proxyReferer=https%3A%2F%2Fwww.google.com%2F
댓글
댓글 쓰기